Distributed data preparation¶
Training data for machine learning models is often transformed before the learning process starts. But sometimes it is more convenient to generate the training data online rather than precomputing it: Maybe the data we want to present to the model depends on the current state of the model, or maybe we want to experiment with different data preparation techniques without having to rerun pipelines. This document is concerned with helping you speed up the data preparation by distributing it across multiple cores or machines.
Data preprocessing can generally be expressed as sink = map(transformation, source), where source is a generator of input data, transformation is the transformation to be applied, and sink is an iterable over the transformed data. We use ZeroMQ to distribute the data processing using a load-balancing message broker illustrated below. Each task (also known as a client) sends one or more messages to the broker from a source. The broker distributes the messages amongst a set of workers that apply the desired transformation. Finally, the broker collects the results and forwards them to the relevant task which act as a sink.
Building an image transformation graph¶
For example, you may want to speed up the process of applying a transformation to an image using the following graph.
import pythonflow as pf
with pf.Graph() as graph:
# Only load the libraries when necessary
imageio = pf.import_('imageio')
ndimage = pf.import_('scipy.ndimage')
np = pf.import_('numpy')
filename = pf.placeholder('filename')
image = (imageio.imread(filename).set_name('imread')[..., :3] / 255.0).set_name('image')
noise_scale = pf.constant(.25, name='noise_scale')
noise = (1 - np.random.uniform(0, noise_scale, image.shape)).set_name('noise')
noisy_image = (image * noise).set_name('noisy_image')
angle = np.random.uniform(-45, 45)
rotated_image = ndimage.rotate(noisy_image, angle, reshape=False).set_name('rotated_image')
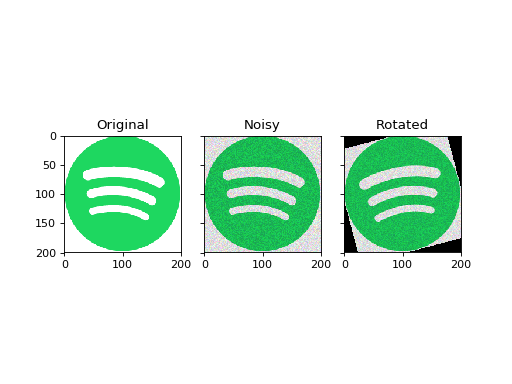
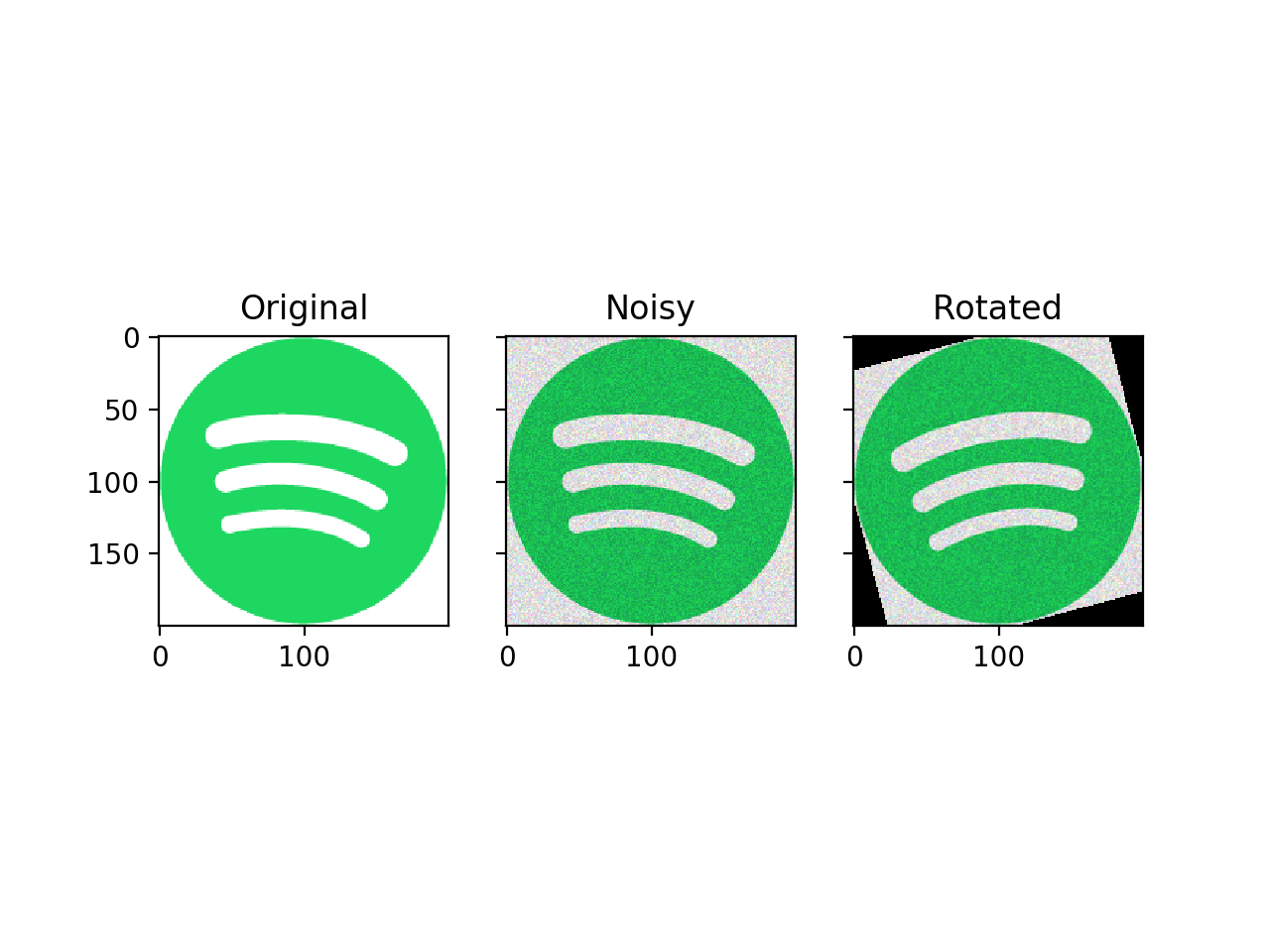
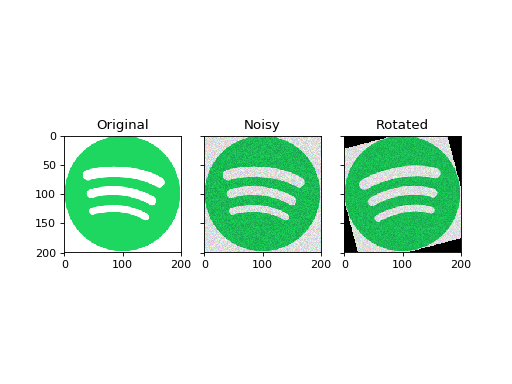
Let’s run the default pipeline using the Spotify logo.
context = {'filename': 'docs/spotify.png'}
graph('rotated_image', context)
Because the context keeps track of all computation steps, we have access to the original image, the noisy image, and the rotated image:
(Source code, png, hires.png, pdf)
{kind=link}
{kind=link}
Distributing the workload¶
Pythonflow provides a straightforward interface to turn your graph into a processor for distributed data preparation:
from pythonflow import pfmq
backend_address = 'tcp://address-that-workers-should-connect-to'
worker = pfmq.Worker.from_graph(graph, backend_address)
worker.run()
Running the processors is up to you and you can use your favourite framework such as ipyparallel or Foreman.
Consuming the data¶
Once you have started one or more processors, you can create a message broker to facilitate communication between tasks and workers.
broker = pfmq.MessageBroker(backend_address)
broker.run_async()
request = {
'fetches': 'rotated_image',
'context': {'filename': 'docs/spotify.png'}
}
rotated_image = broker.apply(request)
The call to run_async starts the message broker in a background thread. To avoid serialization overhead, only the explicitly requested fetches are sent over the wire and the context is not updated as in the example above.
Calling the consumer directly is useful for debugging, but in most applications you probably want to process more than one example as illustrated below.
iterable = broker.imap(requests)
Using imap rather than using the built-in map applied to broker.apply has significant performance benefits: the message broker will dispatch as many messages as there are connected workers. Using the built-in map will only use one worker at a given time.
Note
By default, the consumer and processors will use pickle to (de)serialize all messages. You may want to consider your own serialization format or use msgpack.
Note
Pythonflow does not resend lost messages and your program will not recover if a message is lost.